

訓練AlphaFold2以及使用其進行蛋白質結構預測的推理計算,需要怎樣的計算力支持?
來源:www.ddweb5.com | 發布時間:2022年05月13日訓練AlphaFold2以及使用AlphaFold2進行蛋白質結構預測的推理計算,需要怎樣的計算力支持?濟南戴爾服務器代理商告訴你,戴爾科技中國研究院以及戴爾數據中心業務部解決方案團隊,通過在GitHub下載AlphaFold2模型代碼,部署在戴爾Dell PowerEdge XE8545服務器上,使用NVIDIA A100 GPU測試AlphaFlod2對68-2750個氨基酸殘基組成的不同大小的蛋白質進行3D結構預測,對AlphaFold2的計算性能和特性進行評估。

戴爾PowerEdge XE8545是戴爾科技最新推出的15G服務器家族中,專門針對AI GPU計算進行設計和優化的加速服務器。4U空間內可以支持4張A100 GPU加速卡,GPU之間通過NVLink實現600GB/s的pear-to-pear高速直連通信。
測試環境硬件及軟件配置如下:
●AMD EPYC 7713 64-Core Processor × 2
●1024 GB memory
●Nvidia A100 GPUs × 4, 80GB/500W
●CentOS Linux 7.0
●Python 3.8.0, TensorFlow 2.5.0
●CUDA 11.5, cuDNN 8.3
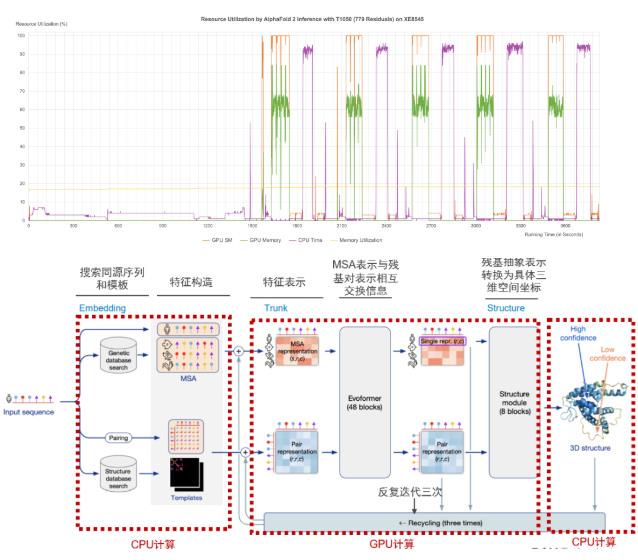
戴爾XE8545服務器推理68-2750個氨基酸殘基組成的蛋白質的3D結構預測耗費的計算時間如下表所示(Top 1模型,即推薦置信度佳的模型),使用單張A100推理計算時間從19.3分鐘到2個半小時不等。

如果按照DeepMind論文Top5模型,XE8545單卡A100推理計算時間如下:
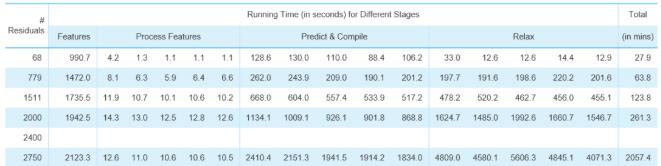
通過性能日志分析,我們可以明顯地看到AlphaFold2在推理過程中,由CPU和GPU交替計算,第 一階段同源序列搜索、模版搜索及特征構造,以及后階段3D結構生成的計算過程主要由CPU計算;中間第二個階段Evoformer神經網絡和結構模塊計算則主要由GPU進行計算。而戴爾XE8545服務器所提供的強勁GPU算力與AMD 多核CPU算力(128核),則能夠確保AlphaFold2在規定時間內完成一個大型的蛋白質3D結構的預測計算。
我們也對比了不同GPU對于AlphaFold2推理計算性能的影響。我們選取了一臺戴爾7750工作站,配置一張NVIDIA RTX5000顯卡,對蛋白質結構預測(Top 1模型)計算性能進行對比,對比結果如下表所示:
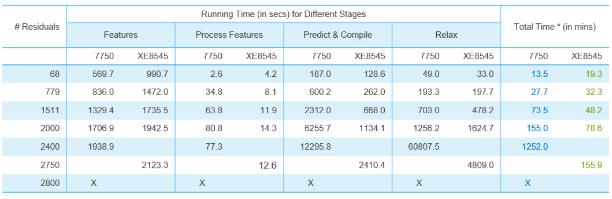
實驗數據顯示:當蛋白質規模很小的時候,企業級與消費級GPU性能相差不大;越大的蛋白質,使用A100結構預測加速性能越明顯。預測1511個殘基的蛋白質3D結構,戴爾XE8545服務器+A100耗費時間是RTX5000的65%;預測2000個殘基的蛋白質3D結構,XE8545耗費的時間只有RTX5000的50%。
我們可以看到,當預測2800個殘基的蛋白質結構時,RTX5000由于顯存容量和算力的限制,無法完成結構預測工作,而XE8545仍然以小時級的時間順利完成同等規模的蛋白質結構預測。
從模型訓練的角度來看,Alphafold2以及后續出現的類似的蛋白質結構預測模型,由于采用Transformer機制,模型訓練需要非常高的計算力,通常需要64-512張GPU組成計算集群,采用分布式訓練機制,才能在比較短的時間內實現模型收斂。
DeepMind在論文中談到,訓練AlphaFold2模型使用128塊Google TPU芯片,接近2周時間完成模型訓練。2022年3月,上海交通大學與潞晨科技發布的FastFold模型,使用256張A100 GPU進行初始訓練和512張A100進行Fine-tuning,2.81天完成模型訓練。
戴爾科技AI GPU分布式訓練解決方案,能夠提供高速GPU計算、小文件IO快速讀寫(蛋白質數據庫存在大量小文件)和高帶寬低延遲地網絡通信,幫助用戶實現在深度學習框架下分布式訓練的自動化實現與性能優化,輕松應對AI時代浪潮。
【相關文章】






+
 微信號:掃碼加微信
微信號:掃碼加微信
微信號:掃碼加微信
 添加微信
添加微信
 聯系我們
聯系我們
 電話咨詢
電話咨詢